Обучающая выборка действительно не репрезентативна
Бывает, что источником нерепрезентативности выборки являются не изменения во времени, а особенности процесса, породившего данные. У банка, где я работал, раньше существовала политика: нельзя выдавать кредиты людям, у которых платежи по текущим долгам превышают 40% дохода. С одной стороны, это разумно, ибо высокая кредитная нагрузка часто приводит к банкротству, особенно в кризисные времена. С другой стороны, и доход, и платежи по кредитам мы можем оценивать лишь приближённо. Возможно, у части наших несложившихся клиентов дела на самом деле были куда лучше. Да и в любом случае, специалист, который зарабатывает 200 тысяч в месяц, и 100 из них отдаёт в счёт ипотеки, может быть перспективным клиентом. Отказать такому в кредитной карте — потеря прибыли. Можно было бы надеяться, что модель будет хорошо ранжировать клиентов даже с очень высокой кредитной нагрузкой… Но это не точно, ведь в обучающей выборке нет ни одного такого!
Мне повезло, что за три года до моего прихода коллеги ввели простое, хотя и страшноватое правило: примерно 1% случайно отобранных заявок на кредитки одобрять в обход почти всех политик. Этот 1% приносил банку убытки, но позволял получать репрезентативные данные, на которых можно обучать и тестировать любые модели. Поэтому я смог доказать, что даже среди вроде бы очень закредитованных людей можно найти хороших клиентов. В результате мы начали выдавать кредитки людям с оценкой кредитной нагрузки от 40% до 90%, но с более жёстким порогом отсечения по предсказанной вероятности дефолта.
Если бы подобного потока чистых данных не было, то убедить менеджмент, что модель нормально ранжирует людей с нагрузкой больше 40%, было бы сложно. Наверное, я бы обучил её на выборке с нагрузкой 0-20%, и показал бы, что на тестовых данных с нагрузкой 20-40% модель способна принять адекватные решения. Но узенькая струйка нефильтрованных данных всё-таки очень полезна, и, если цена ошибки не очень высока, лучше её иметь. Подобный совет даёт и Мартин Цинкевич, ML-разработчик из Гугла, в своём руководстве по машинному обучению. Например, при фильтрации электронной почты 0.1% писем, отмеченных алгоритмом как спам, можно всё-таки показывать пользователю. Это позволит отследить и исправить ошибки алгоритма.
Что умеет Mi Band без смартфона?
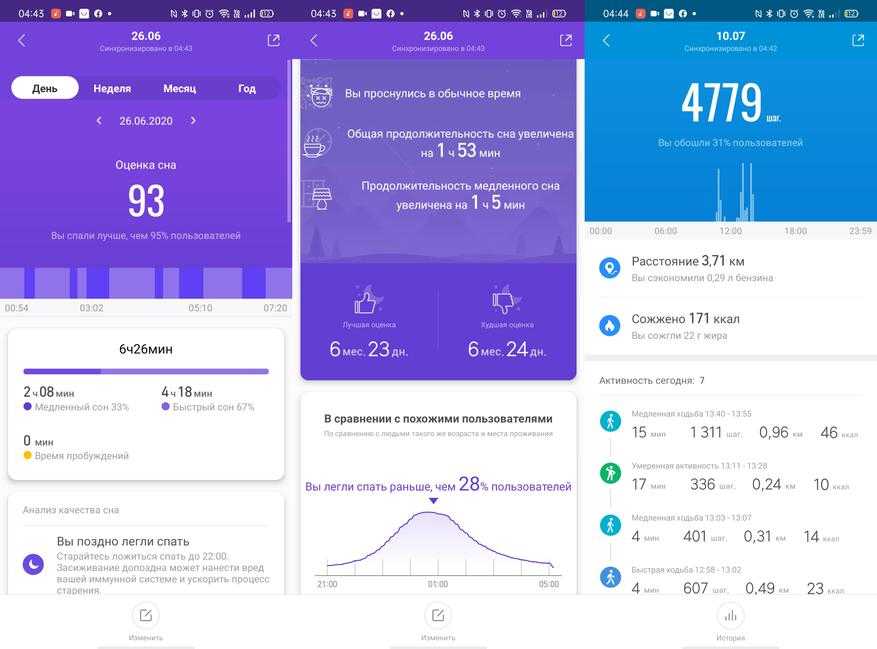
В некоторых разделах мелькают иероглифы. Status демонстрирует количество пройденных за сегодня шагов, дистанцию, сожженные калории и счетчик уведомлений о неактивности. Здесь же отображается статистика по шагам за последнюю неделю, отдельно по каждому дню.
PAI (персональный индекс активности) определяет условный накопительный показатель активности, который растет при увеличении интенсивности тренировок и времени с повышенным пульсом.
Пульсометр откровенно не слишком точный. Pulse позволяет измерить мгновенное значение или посмотреть информацию, накопленную за день с учетом различных состояний. Тоже самое, но подробнее можно найти в приложении.
Notifications настраиваются в Mi Fit выбором определенных синхронизируемых приложений. Приходят только свежие — подключить браслет и получить все пропущенное не выйдет.
Сообщения приходят стабильно, проблем с кириллицей нет. Stress в попугаях по 100-балльной шкале определяет «уровень стресса», Breathing предлагает заняться дыхательной гимнастикой на основе этих данных.
Events — те же Notifications, но для оповещений, настроенных в Mi Fit, и системных сообщений.
В дополнительных фишках можно запутаться. Weather умеет показывать прогноз на несколько дней вперед с подробностями. Но не из самых точных для России источников, и только при синхронизации со смартфоном.
Workout стоит рассмотреть подробно — этот раздел в Mi Band 5 серьезно изменился по сравнению с предшественниками.
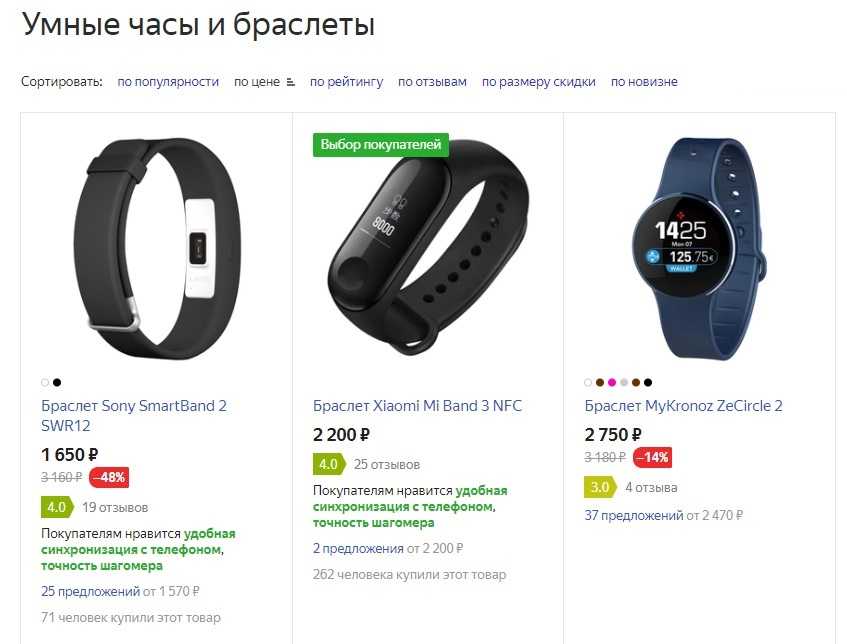
Сравнение Mi Band 3 и 4: в чём отличия?
Главные нововведения в Mi Band 4 – это большой цветной AMOLED-экран и повышенное время автономной работы. Кроме того, компания Xiaomi встроила в новый фитнес-браслет поддержку управления воспроизведением музыки на телефоне (можно переключать треки, регулировать громкость и так далее), а также добавила ещё несколько «программных фич».







Увеличенный экран (чья площадь на 40% выше, чем у предшественника) вмещает больше полезной информации. Это очень полезно для людей, которые привыкли просматривать уведомления и подобные сообщения непосредственно на дисплее фитнес-браслета.
Поработали и над автономностью:
- Вместо Bluetooth 4 версии теперь используется новейший энергоэффективный протокол Bluetooth 5.0;
- Пульсометр при работе теперь потребляет меньше энергии, благодаря чему Mi Band 4 в режиме регулярного измерения пульса «живёт» дольше.
В целом, если третье поколение при активной эксплуатации с измерением пульса каждые 10 минут, включённым отслеживанием сна и 200-300 уведомлениями с вибрацией в день могло проработать от одной зарядки около недели, то четвёртое – уже 9-10 дней.
Также девайс получил поддержку кастомизации интерфейса. Можно настраивать цвета, стиль и циферблаты. Это поможет сделать фитнес-браслет более индивидуальным и удобным в использовании.
Характеристики Mi Band 4
| Экран | 0,95 дюймов, AMOLED, разрешение 240×120 пикселей, сенсорный |
| Покрытие передней панели | Толстое изогнутое стекло |
| Пульсометр | Есть |
| Гироскоп, акселерометр | Есть, 6-осевой |
| Определяемые виды активности | Бег (улица, беговая дорожка), ходьба, езда на велосипеде, плавание, фитнес и воркаут |
| Связь с телефоном | Отображает уведомления, сообщает о вызовах и СМС-сообщениях, вибрация |
| Интерфейс связи | Bluetooth 5.0 |
| Стандарт влагозащиты | IP68, выдерживает погружение на глубину до 50 м |
| Ёмкость аккумулятора | 135 мАч |
| Время автономной работы | До 20 дней в зависимости от режима |
| Совместимость | Android, iOS |
Mi Band 4 – основные функции
Стоит отметить, что существует версия с NFC и встроенным голосовым помощником. Однако за пределами Китая и некоторых других азиатских стран эти функции бесполезны.
Основные возможности Ми Бенд 4 заключаются в следующем:
Кастомизация (индивидуальная настройка) интерфейса. Можно выбрать циферблат из огромного количества, цветовую схему, стиль. Это сделает фитнес-браслет более индивидуальным. Новые циферблаты для Ми Бенд 4 можно скачать непосредственно из приложения Mi Fit;
Управление воспроизведением музыки на телефоне прямо с браслета. Можно переключать треки, ставить на паузу и регулировать громкость без необходимости лезть в карман;
Определение и трекинг расширенного числа видов физической активности. Фитнес-трекер способен отслеживать не только ходьбу, бег и тренировки, но также плавание и езду на велосипеде. Разумеется, следить за качеством сна и сердцебиением новый умный браслет также может;





Водозащита 5 АТМ. Трекер можно не снимать во время плавания и ныряния – устройство выдерживает погружение на глубину до 50 метров;
До 9-10 дней автономной работы в режиме активного использования.
Технология
NFC — способ передачи данных на небольшом расстоянии. Радиус действия составляет около 10 сантиметров. Радиосигнал передается от одного объекта к другому за несколько секунд, при этом затрачивается гораздо меньше энергии, чем при использовании Bluetooth. Чип очень маленький, поэтому он легко интегрируется в смартфоны и фитнес браслеты. Через датчик можно передать ссылку на страницу сайта/приложение в Play Market, координаты и маршрут, анкеты контактов.
Работа основана на программируемых метках, к которым можно привязать определенное действие. Далее устройство с чипом подносится к метке и происходит выполнение команды.
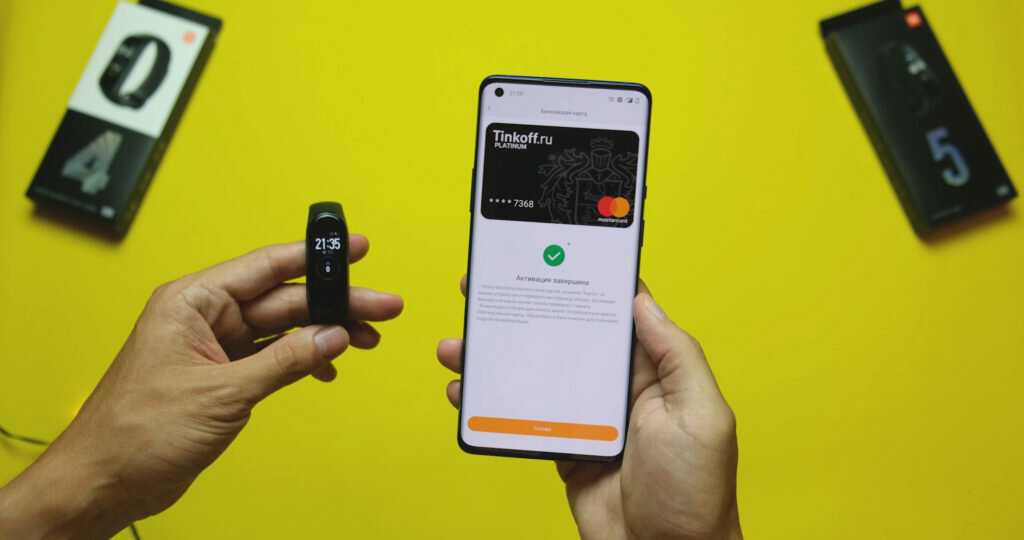
Возникает логичный вопрос: а как реализована защита платежных инструментов? Ответ прост — для подтверждения оплаты нужно поднести палец к сканеру отпечатков. К тому же, номер карты шифруется, а на iPhone используется FaceID, который практически невозможно обойти. Безопасность высочайшего класса.
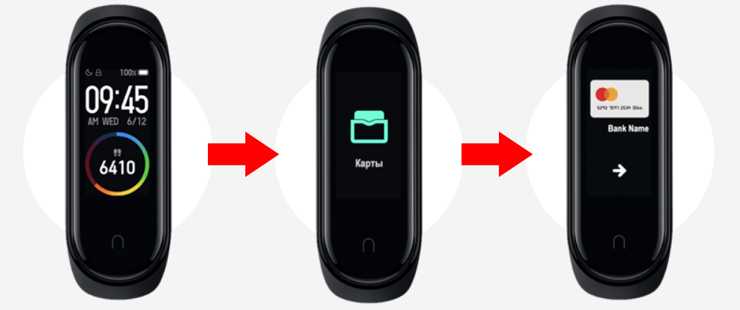
Как оплачивать браслетом Mi Band 4 NFC
Осуществление платежа может происходить даже без подключения Mi Band 4 NFC к смартфону. Для этого следуйте нашей инструкции:
- Активируйте дисплей нажатием сенсорной кнопки под экраном.
- Если требуется, введите 4-х значный код для разблокировки браслета.
- Пролистайте меню до раздела «Карты».
- Выберите ту, которой хотите рассчитаться.
- Нажмите на стрелочку для совершения платежа.
Как только вы поднесете Mi Band близко к терминалу, транзакция подтвердится вибрацией браслета.
Важно! Если в течение 60 секунд деньги не спишутся, процедуру оплаты придется повторить сначала. Иногда для совершения транзакции может потребоваться ввод пин-кода на POS терминале.

Рождение легенды
Пользователям, которые только знакомятся с умными браслетами Сяоми, и планируют купить Ми Бэнд 5, будет интересно узнать про историю презентаций популярного гаджета.
- Июль 2014 – Сяоми представила свой первый умный браслет на рынке. Функционал Ми Бэнд тогда был крайне ограничен, а дизайн максимально прост.
- Июнь 2016 – выходит бестселлер ближайших двух лет Mi Band 2. Благодаря этому гаджету компания установила несколько рекордов продаж по всему миру.
- Май 2018 – на юбилейной конференции представили долгожданный Mi Band 3. Производитель впервые добавил поддержку NFC для бюджетных носимых устройств. Бесконтактные платежи работали только на территории Китая.
- 11 июня 2019 – четвертое поколение запомнилось фанатам цветным экраном. Новинку тогда максимально быстро завезли в европейские магазины. Глобальная версия получила название Mi Smart Band 4. В конце мая 2020 года в России представили версию с NFC, которая получила полноценную поддержку Mastercard.
Модель очень трудно внедрить
Если модель основана на данных «из будущего», с этим вряд ли что-то можно поделать. Но часто бывает так, что даже с доступными данными внедрение модели даётся нелегко. Настолько нелегко, что внедрение затягивается на неопределённый срок из-за нехватки трудовых ресурсов на это. Что же так долго делают разработчики, если модель уже создана?






Скорее всего, они переписывают весь код с нуля. Причины на это могут быть совершенно разные. Возможно, вся их система написана на java, и они не готовы пользоваться моделью на python, ибо интеграция двух разных сред доставит им даже больше головной боли, чем переписывание кода. Или требования к производительности так высоки, что весь код для продакшна может быть написан только на C++, иначе модель будет работать слишком медленно. Или предобработку признаков для обучения модели вы сделали с использованием SQL, выгружая их из базы данных, но в бою никакой базы данных нет, а данные будут приходить в виде json-запроса.
Если модель создавалась в одном языке (скорее всего, в python), а применяться будет в другом, возникает болезненная проблема её переноса. Есть готовые решения, например, формат PMML, но их применимость оставляет желать лучшего. Если это линейная модель, достаточно сохранить в текстовом файле вектор коэффициентов. В случае нейросети или решающих деревьев коэффициентов потребуется больше, и в их записи и чтении будет проще ошибиться. Ещё сложнее сериализовать полностью непараметрические модели, в частности, сложные байесовские. Но даже это может быть просто по сравнению с созданием признаков, код для которого может быть совсем уж произвольным. Даже безобидная функция в разных языках программирования может означать разные вещи, что уж говорить о коде для работы с картинками или текстами!
Даже если с языком программирования всё в порядке, вопросы производительности и различия в формате данных в учении и в бою остаются. Ещё один возможный источник проблем: аналитик при создании модели активно пользовался инструментарием для работы с большими таблицами данных, но в бою прогноз необходимо делать для каждого наблюдения по отдельности. Многие действия, совершаемые с матрицей n*m, с матрицей 1*m проделывать неэффективно или вообще бессмысленно. Поэтому аналитику полезно с самого начала проекта готовиться принимать данные в нужном формате и уметь работать с наблюдениями поштучно. Мораль та же, что и в предыдущем разделе: начинайте тестировать весь пайплайн как можно раньше!
Разработчикам и админам продуктивной системы полезно с начала проекта задуматься о том, в какой среде будет работать модель. В их силах сделать так, чтобы код data scientist’a мог выполняться в ней с минимумом изменений. Если вы внедряете предсказательные модели регулярно, стоит один раз создать (или поискать у внешних провайдеров) платформу, обеспечивающую управление нагрузкой, отказоустойчивость, и передачу данных. На ней любую новую модель можно запустить в виде сервиса. Если же сделать так невозможно или нерентабельно, полезно будет заранее обсудить с разработчиком модели имеющиеся ограничения. Быть может, вы избавите его и себя от долгих часов ненужной работы.
Модель невозможно внедрить
Бывает, что созданная аналитиками модель демонстрирует хорошие меры как точности прогноза, так и экономического эффекта. Но когда начинается её внедрение в продакшн, оказывается, что необходимые для прогноза данные недоступны в реальном времени. Иногда бывает, что это настоящие данные «из будущего». Например, при прогнозе крепости пива важным фактором является измерение его плотности после первого этапа брожения, но применять прогноз мы хотим в начале этого этапа. Если бы мы не обсудили с заказчиком точную природу этого признака, мы бы построили бесполезную модель.
Ещё более неприятно может быть, если на момент прогноза данные доступны, но по техническим причинам подгрузить их в модель не получается. В прошлом году мы работали над моделью, рекомендующей оптимальный канал взаимодействия с клиентом, вовремя не внёсшим очередной платёж по кредиту. Должнику может звонить живой оператор (но это не очень дёшево) или робот (дёшево, но не так эффективно, и бесит клиентов), или можно не звонить вообще и надеяться, что клиент и так заплатит сегодня-завтра. Одним из сильных факторов оказались результаты звонков за вчерашний день. Но оказалось, что их использовать нельзя: логи звонков перекладываются в базу данных раз в сутки, ночью, а план звонков на завтра формируется сегодня, когда известны данные за вчера. То есть данные о звонках доступны с лагом в два дня до применения прогноза.
На моей практике несколько раз случалось, что модели с хорошей точностью откладывались в долгий ящик или сразу выкидывались из-за недоступности данных в реальном времени. Иногда приходилось переделывать их с нуля, пытаясь заменить признаки «из будущего» какими-то другими. Чтобы такого не происходило, первый же небесполезный прототип модели стоит тестировать на потоке данных, максимально приближенном к реальному. Может показаться, что это приведёт к дополнительным затратам на разработку тестовой среды. Но, скорее всего, перед запуском модели «в бою» её придётся создавать в любом случае. Начинайте строить инфраструктуру для тестирования модели как можно раньше, и, возможно, вы вовремя узнаете много интересных деталей.
Прогноз используется неэффективно
Как правило, решение, принимаемое на основе прогноза модели, является лишь небольшой частью какого-то бизнес-процесса, и может взаимодействовать с ним причудливым образом. Например, большая часть заявок на кредитки, одобренных автоматическим алгоритмом, должна также получить одобрение живого андеррайтера, прежде чем карта будет выдана. Когда мы начали одобрять заявки с высокой кредитной нагрузкой, андеррайтеры продолжили их отказывать. Возможно, они не сразу узнали об изменениях, или просто решили не брать на себя ответственность за непривычных клиентов. Нам пришлось передавать кредитным специалистам метки типа «не отказывать данному клиенту по причине высокой нагрузки», чтобы они начали одобрять такие заявки. Но пока мы выявили эту проблему, придумали решение и внедрили его, прошло много времени, в течение которого банк недополучал прибыль. Мораль: с другими участниками бизнес-процесса нужно договариваться заранее.
Иногда, чтобы зарезать пользу от внедрения или обновления модели, другое подразделение не нужно. Достаточно плохо договориться о границах допустимого с собственным менеджером. Возможно, он готов начать одобрять клиентов, выбранных моделью, но только если у них не более одного активного кредита, никогда не было просрочек, несколько успешно закрытых кредитов, и есть двойное подтверждение дохода. Если почти весь описанный сегмент мы и так уже одобряем, то модель мало что изменит.
Впрочем, при грамотном использовании модели человеческий фактор может быть полезен. Допустим, мы разработали модель, подсказывающую сотруднику магазина одежды, что ещё можно предложить клиенту, на основе уже имеющегося заказа. Такая модель может очень эффективно пользоваться большими данными (особенно если магазинов — целая сеть). Но частью релевантной информации, например, о внешнем виде клиентов, модель не обладает. Поэтому точность угадывания ровно-того-наряда-что-хочет-клиент остаётся невысокой. Однако можно очень просто объединить искусственный интеллект с человеческим: модель подсказывает продавцу три предмета, а он выбирает из них самое подходящее. Если правильно объяснить задачу всем продавцам, можно прийти к успеху.
Модель нестабильная
Бывает, что модель прошла все тесты, и была внедрена без единой ошибки. Вы смотрите на первые решения, которые она приняла, и они кажутся вам осмысленными. Они не идеальны — 17 партия пива получилась слабоватой, а 14 и 23 — очень крепкими, но в целом всё неплохо. Проходит неделя-другая, вы продолжаете смотреть на результаты A/B теста, и понимаете, что слишком крепких партий чересчур много. Обсуждаете это с заказчиком, и он объясняет, что недавно заменил резервуары для кипячения сусла, и это могло повысить уровень растворения хмеля. Ваш внутренний математик возмущается «Да как же так! Вы мне дали обучающую выборку, не репрезентативную генеральной совокупности! Это обман!». Но вы берёте себя в руки, и замечаете, что в обучающей выборке (последние три года) средняя концентрация растворенного хмеля не была стабильной. Да, сейчас она выше, чем когда-либо, но резкие скачки и падения были и раньше. Но вашу модель они ничему не научили.








Другой пример: доверие сообщества финансистов к статистическим методам было сильно подорвано после кризиса 2007 года. Тогда обвалился американский ипотечный рынок, потянув за собой всю мировую экономику. Модели, которые тогда использовались для оценки кредитных рисков, не предполагали, что все заёмщики могут одновременно перестать платить, потому что в их обучающей выборке не было таких событий. Но разбирающийся в предмете человек мог бы мысленно продолжить имеющиеся тренды и предугадать такой исход.
Бывает, что поток данных, к которым вы применяете модель, стационарен, т.е. не меняет своих статистических свойств со временем. Тогда самые популярные методы машинного обучения, нейросетки и градиентный бустинг над решающими деревьями, работают хорошо. Оба этих метода основаны на интерполяции обучающих данных: нейронки — логистическими кривыми, бустинг — кусочно-постоянными функциями. И те, и другие очень плохо справляются с задачей экстраполяции — предсказания для X, лежащих за пределами обучающей выборки (точнее, её выпуклой оболочки).
Некоторые более простые модели (в том числе линейные) экстраполируют лучше. Но как понять, что они вам нужны? На помощь приходит кросс-валидация (перекрёстная проверка), но не классическая, в которой все данные перемешаны случайным образом, а что-нибудь типа TimeSeriesSplit из sklearn. В ней модель обучается на всех данных до момента t, а тестируется на данных после этого момента, и так для нескольких разных t. Хорошее качество на таких тестах даёт надежду, что модель может прогнозировать будущее, даже если оно несколько отличается от прошлого.
Иногда внедрения в модель сильных зависимостей, типа линейных, оказывается достаточно, чтобы она хорошо адаптировалась к изменениям в процессе. Если это нежелательно или этого недостаточно, можно подумать о более универсальных способах придания адаптивности. Проще всего калибровать модель на константу: вычитать из прогноза его среднюю ошибку за предыдущие n наблюдений. Если же дело не только в аддитивной константе, при обучении модели можно перевзвесить наблюдения (например, по принципу экспоненциального сглаживания)
Это поможет модели сосредоточить внимание на самом недавнем прошлом
Даже если вам кажется, что модель просто обязана быть стабильной, полезно будет завести автоматический мониторинг. Он мог бы описывать динамику предсказываемого значения, самого прогноза, основных факторов модели, и всевозможных метрик качества. Если модель действительно хороша, то она с вами надолго. Поэтому лучше один раз потрудиться над шаблоном, чем каждый месяц проверять перформанс модели вручную.



